
Il existe une multitude d’outils de CI/CD, le plus connu étant sans doute Jenkins. Ce dernier propose depuis quelques temps deux approches pour construire nos pipelines : Scripted Pipeline et Declarative Pipeline, les deux étant généralement codés en Groovy dans un “Jenkinsfile”. La seconde approche est supposée être plus simple d’utilisation mais reste assez liée au Groovy (ou autre DSL).
Jenkins peut interagir avec Docker, permettant de définir des pipelines composés de stages (d’étapes) tournant dans des conteneurs. De cette façon, chaque étape du build tourne dans un environnement contrôlé sans avoir besoin de maintenir de serveurs slaves, tout en offrant une mise à l’échelle précise puisque les conteneurs utilisés peuvent être automatiquement détruits à la fin d’une stage. Néanmoins la mise en place de ce type de mécanismes sous Jenkins demande un peu de travail.
Parmi les alternatives à Jenkins (comme GoCD ou Drone.io), je vous propose d’en découvrir une un peu moins connue mais tout aussi intéressante : Concourse CI.
Concourse CI, un Nième outil de CI/CD ?
L’intégration continue permet d’automatiser la construction d’un projet, l’exécution des tests de ce projet, mais aussi de lancer des analyses sur le code source… bref des tâches souvent rébarbatives et chronophages pour un développeur.
Concourse CI s’inscrit dans la lignée des outils dédiés à ce type d’automatisation.
Mais pourquoi utiliser Concourse alors qu’il existe déjà Jenkins, GoCD, Gitlab CI, Drone et j’en passe ? Tout simplement parce que Concourse présente le gros avantage d’être léger et très simple à mettre en oeuvre… et c’est rafraîchissant d’avoir enfin un outil de CI qui ne soit pas une usine à gaz !
Concourse donne l’impression d’être une solution d’intégration continue développée par les développeurs et pour les développeurs. A ce sujet, ce projet est développé en GO et supporté par Pivotal, connue notamment pour le framework Spring.
La véritable force de Concourse face à Jenkins, est de proposer nativement du Declarative pipeline reposant sur des conteneurs. Chaque tâche de build tourne dans un conteneur docker. Nul besoin de spécifier que telle ou telle étape doit être exécutée au sein d’un conteneur comme on pourrait le faire dans un Jenkinsfile. On décrit donc le pipeline avec une grande facilité, pipeline qui sera du même coup épuré de toute instruction pouvant en alourdir la lisibilité. D’ailleurs, pas de Groovy dans les pipelines Concourse, on décrit ce que l’on attend de notre pipeline dans un fichier Yaml.
Les concepts fondamentaux sont peu nombreux et simples à assimiler, comme on pourra le voir dans la partie suivante.
Concepts fondamentaux de Concourse CI
Avant toute chose, il est important de préciser que Concourse dispose d’une interface graphique, mais que celle ci ne permet que de visualiser nos pipelines, et en aucun cas d’agir sur eux (pour cela on utilise l’outil en ligne de commande fly qui sera présenté dans la troisième partie de cet article).
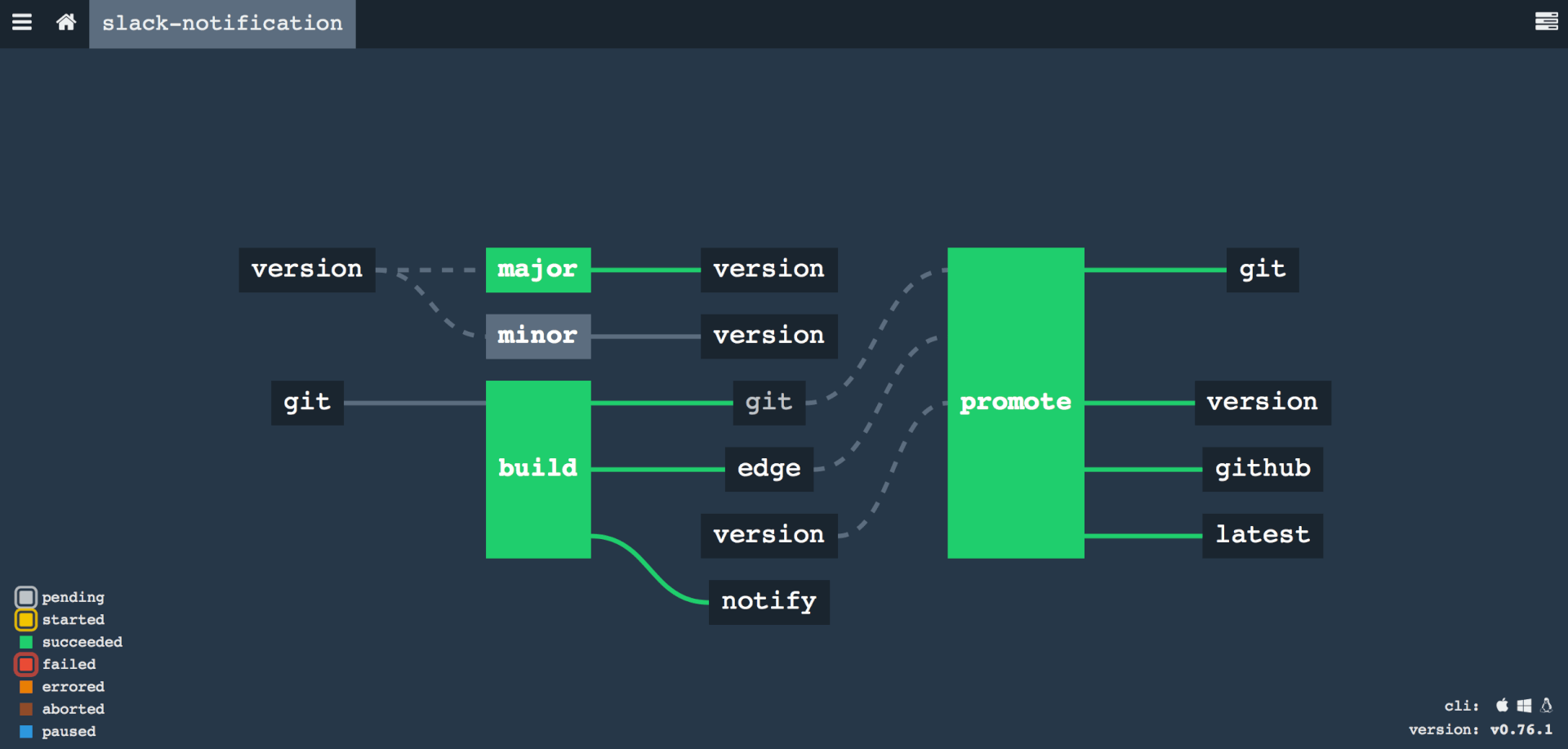
Comme énoncé un peu plus haut, Concourse prône la simplicité comme le montre le schéma d’architecture suivant :
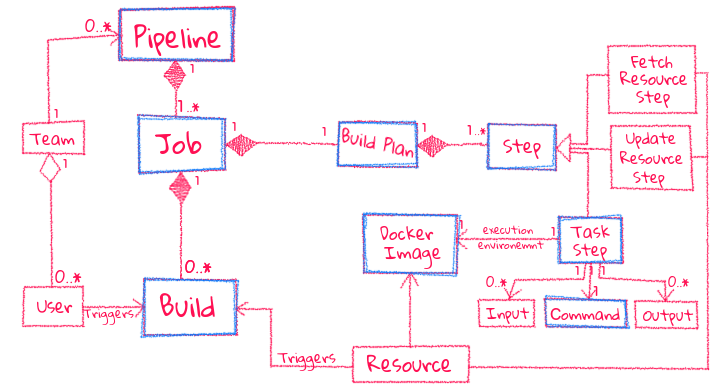
En somme, il y a peu de notions a assimiler pour comprendre comment fonctionne l’outil. Une fois que les concepts de Task, Job, et Resource sont assimilés, alors 80 % de l’outil est maîtrisé.
-
Pipeline et Job
Un pipeline est généralement constitué de ressources, parfois de déclarations de type de ressource, et d’un (ou plusieurs) Jobs . C’est au sein de ces jobs qu’on définit les ressources et tâches (tasks). Un job n’est donc qu’un agrégateur / séquenceur de steps.
resource_types:
- name: sample-type
...
resources:
- name: sample-resource-repository
type: sample-type
...
jobs:
- name: sample-job-1
plan:
- task: sample-task-1
...
- name: sample-job-2
plan:
- task: sample-task-2
...
-
Ressource
Autre notion importante, la ressource permet à notre pipeline d’importer les éléments nécessaires au build, ou d’exporter des informations réutilisables ultérieurement. Une des ressources les plus utilisées est celle permettant de récupérer le code source d’un projet depuis un repo GitHub (nous aurons l’occasion de l’aborder un peu plus loin). Celle ci permet de télécharger un projet, mais nous pouvons également appliquer certains paramètres sur nos steps pour, par exemple, déclencher le pipeline à chaque commit sur une branche spécifique ou tagger dès qu’un build se termine…
En outre, il existe deux steps particulières qui permettent de faire des push ou checkout du code depuis un repository (respectivement put et get).
Les ressources ne se cantonnent pas à l’utilisation de repository GitHub, il en existe une multitude mises à disposition par la communauté (ex: connexion avec Artifactory).
Ci-dessous quelques ressources utiles :
- https://github.com/concourse/git-resource – push et checkout sur un repository Git
- https://github.com/concourse/s3-resource – interaction avec AWS S3
- https://github.com/concourse/cf-resource – interaction avec CloudFoundry
- https://github.com/pivotalservices/artifactory-resource – interaction avec JFrog Artifactory
- https://github.com/concourse/docker-image-resource – push d’image sur docker-registry
- https://github.com/tomwhoiscontrary/maven-repo-resource – interaction avec repository Maven
- https://github.com/concourse/concourse-pipeline-resource – interaction avec les pipelines Concourse
- https://github.com/cloudfoundry-community/slack-notification-resource – Lancement d’analyses SonarQube et contrôle des quality gates
Pour résumer il faut voir les ressources comme des connecteurs permettant de récupérer (ou téléverser) des données depuis différentes sources (Git, Nexus, …), qui seront utilisées ensuite durant le build.
Dans l’exemple suivant, on définit une ressource permettant de se connecter à un repository Git, et de récupérer le code source via une step de type “get”.
resources:
- name: sample-repo
type: git
source:
uri: https://github.com/sample/sample_repo.git
jobs:
- name: sample
plan:
- get: sample-repo
-
Task
C’est la brique de base des pipelines Concourse. Chaque task est exécutée dans un conteneur Docker par Concourse, et est à ce titre entièrement stateless : Si une tâche a pour but de compiler une application, le résultat de cette compilation sera perdu à la fin de l’exécution de la tâche (le conteneur est automatiquement détruit). Afin de ne pas perdre ce qui à été produit par cette tâche, il est nécessaire de l’exposer dans une output. Les autres tâches du pipeline pourront alors prendre cette output en entrée (en tant qu’input donc) et ainsi réutiliser le résultat produit durant la phase de compilation.
A l’inverse des autres systèmes de CI, on ne lie donc pas directement les tâches entre elles : celles ci sont automatiquement connectées par Concourse en fonction des inputs / outputs que nous définissons dans le pipeline.
resources:
- name: sample-repo
type: git
source:
uri: https://github.com/sample/sample_repo.git
jobs:
- name: sample
plan:
- get: sample-repo
- task: sample-task
config:
platform: linux
image_resource:
type: docker-image
source:
repository: ubuntu
run:
path: sh
args:
- -exc
- |
echo hello
inputs:
- name: sample-repo
Dans l’exemple de pipeline précédent, nous avons défini une ressource (permettant de nous connecter à un repository git) et un job nommé “sample”. Celui-ci est doté d’une step qui récupérera les sources du repo, et d’une tâche qui prendra en input le repo (et affichera le message “hello”). Au sujet de cet affichage, on remarque la présence de mot clé “config” qui permet de spécifier quelle type d’image Docker on souhaite utiliser pour exécuter notre task. Ici la commande “echo” sera donc exécutée dans un conteneur issue d’une image Linux (Ubuntu).
Vous l’aurez remarqué les définitions sont relativement simples a comprendre. Dans le prochain article nous verrons comment mettre en pratique les concepts abordés ici.
Un peu de lecture pour patienter :
- Site officiel : https://concourse-ci.org
- Présentation de Concourse ci au Devoxx 2018 : https://www.youtube.com/watch?v=moiSC3gmCew
- Comparatif des différents outils de CI/CD : https://www.digitalocean.com/community/tutorials/ci-cd-tools-comparison-jenkins-gitlab-ci-buildbot-drone-and-concourse
- Le repository GitHub du projet : https://github.com/concourse

