
Le Devfest est essentiellement connu pour son édition Nantaise, cependant Lille n’est pas en reste et accueille l’événement durant une journée. Certes pour sa deuxième édition (qui a eu lieu le 21 juin), le salon est a plus petite échelle que son cousin de Loire-Atlantique, mais les talks sont variés, les codelabs très intéressants, les goodies présents en quantité… et le tout dans une ambiance conviviale ! Cette année six Ineatiens ont participé aux conférences, l’occasion d’assister à des présentations de qualité et de partager tout ça (avec vous) !
Retour sur une journée riche en découverte.
Un événement orienté technique, mais pas que …
On a souvent tendance a s’arrêter aux contenus des conférences. Oui cette année nous avons pu assister à des talks sur le DevOps, le Big Data ou le développement Web… mais aussi à des Keynotes plus généralistes. Ainsi la Keynote d’ouverture, intitulée “Et si Super Mario était UX Designer ?”, avait pour but de nous sensibiliser à l’ergonomie et illustrait différentes notions par le biais de cas concrets dans les jeux-vidéos. Cette présentation restait assez générale pour ne pas en perdre certains, mais aussi très interactive : les speakeuses ont permis à l’auditoire de participer à un quizz via l’application Kahoot.it (avec en prime un cadeau pour le vainqueur).

Plus générale encore était la Keynote de fermeture dont le sujet était… le speechless ! Le principe ? Les speakers doivent improviser sur un thème tiré au sort (“Post mortem”, “Success story”, …), un sujet fixé par le public (“la Reine des neiges” en success story, IE11 et le Fiat Multipla en Post mortem), et avec des slides qu’ils découvrent au fur et à mesure. L’exercice n’était pas facile, mais ils s’en sont tous très bien sorti.
A boire et à manger
Point essentiel sur un salon : les victuailles ! Le staff avait prévu (pour 20 euros …) petit déjeuner (café, viennoiseries), déjeuner (buffet froid), et “Goûter” l’après midi (gâteau, jus de fruit). Les plus courageux pouvaient également mixer leur propre smoothie sur un des stands, moyennant quelques efforts (le mixeur étant relié au pédalier d’un vélo d’appartement ;)).
Les talks et codelabs
Voici un résumé des sujets auxquels nous avons participé
gRPC, communiquons autrement – Sébastien Friess
Premier talk de la journée, dont l’objectif était de nous faire découvrir gRPC, technologie développée par Google en 2015 et permettant de réaliser des applications client / serveur RPC via HTTP2.

Le talk a débuté par quelques rappels sur TCP/UDP, ainsi qu’un historique des principales technologies d’échange client / serveur (CORBA, RMI, puis SOAP et REST).
Sébastien est ensuite entré dans le vif du sujet en présentant le coeur de gRPC : le “contrat d’interface” entre client et serveur. En effet ce fichier, défini via IDL, contient trois parties :
- La version, le package
- La description des méthodes
- La description des messages
Cette façon d’opérer ne vas pas sans rappeler les contrats d’interface que nous définissions avec RMI. Néanmoins gRPC a un vrai avantage sur RMI : il est supporté par une dizaine de langages. Il supporte également bon nombre de plugins middleware pour, par exemple, faire du load balancing ou du monitoring.
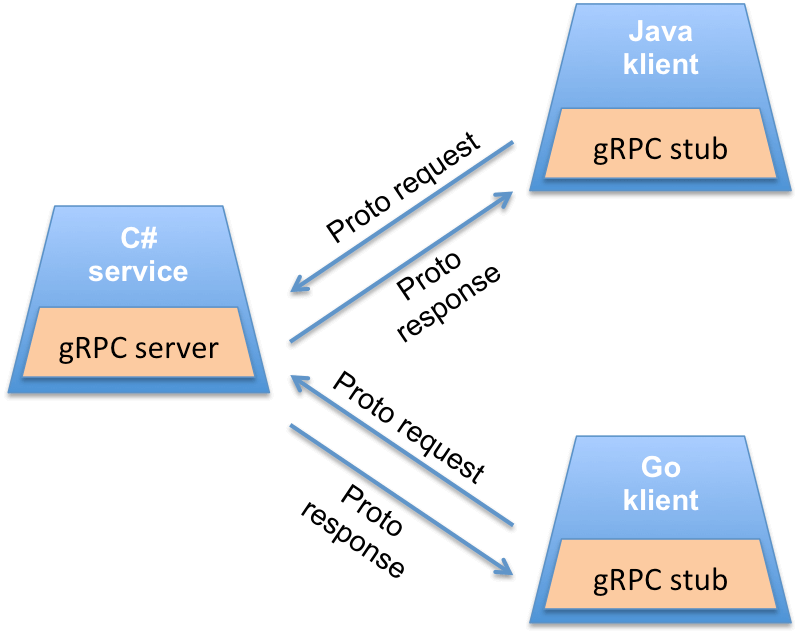
Cette technologie facilite grandement la gestion des versions d’un serveur. Dans le cas d’une application REST, le versioning est souvent complexe et il est généralement nécessaire de dupliquer des URLs en V1, V2, …
Avec gRPC, si une méthode n’existe pas côté serveur, l’erreur est gérée proprement et naturellement (merci notre fichier IDL :)).
La présentation s’est terminée par une petite démo, nous prouvant que gRPC était simple à mettre en oeuvre et robuste. Bien que présentant beaucoup d’avantages, un point noircit un peu le tableau. Définir nos micro-services en passant par un contrat d’interface implique que le client ait connaissance de ce contrat, ce qui peut être un frein réel dans le cas d’APIs ouvertes et en libre accès (pour ce type d’usage REST est sans doute plus adapté). Néanmoins gRPC reste une technologie adaptée quand il s’agit d’établir, sans trop d’efforts, des communications inter-services/applications.
Les slides et le code source de la démo sont disponibles ici
Mathias Deremer-Accettone
Métrologie et Alerting avec Prometheus et Grafana – Christophe Furmaniak & Yoan Rousseau
Aujourd’hui nos SI font intervenir de plus en plus de briques différentes, et sont par conséquent de plus en plus complexes à maintenir. Le monitoring est donc devenu essentiel. Mais que faut-il monitorer et avec quels outils ? C’est par cette question que les speakers ont commencer le second talk.

Après avoir brièvement exploré quelques solutions du marché ils se sont attardés sur l’outil de “métrologie“ Prometheus. L’ architecture a ainsi été passée au crible ce qui a permis de clarifier le fonctionnement des mécaniques internes et mettre en évidence les forces de Prometheus face à d’autres solutions basées sur InfluxDb.
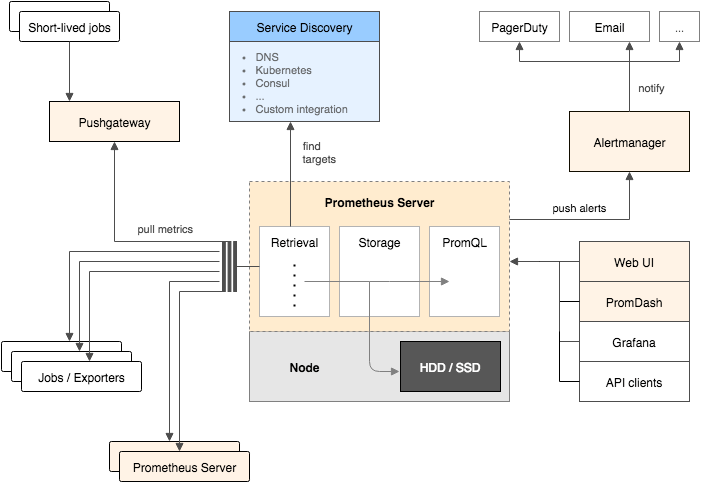
Prometheus a une approche dite “Pull” : ce ne sont pas les services monitorés qui contactent Prometheus (modèle “Push” utilisé par TIG (Telegraf Influxdb Grafana) par exemple), les métriques sont collectées périodiquement grace à des daemons installés sur les services. Charge donc à ces “targets” d’exposer les informations à monitorer. Les métriques récupérées peuvent ensuite être traitées via un langage de requête appelé PromQL, permettant par exemple de définir des alertes afin de prévenir d’une future panne.
Une démonstration a mis en avant la façon dont sont stockées les métriques et sous quel format. Bien que la démo n’ait pas pu être terminée par manque de temps, celle ci nous aura montré qu’il existait quatre types de métrique (Compteur, Gauge, Histogram et Summary) et que Prometheus était facilement interfaçable avec Grafana (qui fournit des dashboards permettant de se connecter à des data-sources et ainsi visualiser ce qui ressort de Prometheus).
Mathias Deremer-Accettone
CodeLab : Tout le monde parle de Kubernetes, et si vous vous y mettiez aussi ? – Nicolas Lassalle & Christophe Furmaniak
Kubernetes est devenu un incontournable dans le domaine de l’orchestration de conteneurs. Christophe et Nicolas nous ont proposé de découvrir cette technologie à travers un codelab. Contrairement aux conférences auxquelles nous avions pu assister, l’idée ici était de privilégier la mise en pratique : il n’y a rien de tel que de mettre les mains dans le cambouis pour comprendre comment fonctionne Kubernetes !

Après une courte introduction, nos deux speakers nous ont partagé une série de TPs a réaliser durant la session. Ils ont fait preuve d’une grande pédagogie et chaque TP était précédé d’une série d’explications et de définitions.
Ainsi nous apprenons que la brique de base d’un déploiement K8s (pour Kubernetes, à l’image de i18n pour Internationalisation ! ) est appelée un Pod et est en réalité un groupe d’un ou plusieurs conteneurs partageant la même IP. Ceux ci peuvent également accéder aux mêmes volumes, sont toujours co-localisés (tournent forcément sur le même noeud) et cogérés (si un Pod est dupliqué, alors tous ses conteneurs le sont aussi).
Le but du premier TP était d’illustrer ces différentes notions, et pour se faire nous avions a disposition une série de namespaces attitrés (là encore la logistique était impeccable).
La séance s’est poursuivie avec les Healthchecks et Replicasets (K8s surveille les conteneurs, et se charge de les redémarrer en cas de crash). Ce second TP nous a permis de manipuler les fichiers de description (au format YML) d’un Pod et ainsi de constater qu’il était aussi simple à prendre en main qu’un fichier docker-compose. De plus, et c’est à mon sens un des avantages principales de Kubernetes, il est possible de spécifier dans ces fichiers Yaml des méta-données (commit id, nom d’un job Jenkins, …) mais aussi et surtout de fournir des paramètres utiles à Kubernetes pour gérer le cycle de vie des Pods.
Un exemple de paramètre : “failureTreshold” qui permet de redémarrer un Pod au bout de X failure.
Du pure déclaratif donc, puisque on “demande” à Kubernetes, via un fichier de configuration, de construire un Pod avec tel et tel conteneurs et de l’administrer selon telle et telle règles. Cette approche est facile à appréhender comparée à ce qu’on peut retrouver sur des solutions comme Rancher (en version 1.x).
Le codelab s’est terminé avec les Ingress, qui permettent de dialoguer avec les composants d’un cluster depuis l’extérieur.
Malheureusement nous n’avons pas pu terminer l’ensemble des exercices faute de temps.
Cependant les speakers nous ont fourni l’ensemble des supports de ce lab, à retrouver ici !
Les plus motivés pourront reproduire les exercices chez eux avec un MiniKube 😉
Pour conclure, un codelab de qualité, on regretta seulement de ne pas avoir bénéficié d’un accès au Wifi (et du fait d’être passé par la 4G de nos téléphones pour faire les TPs).
Mathias Deremer-Accettone
ESM : EcmaScript Modules in browser and NodeJS. It’s about time ! –
Sébastien Pertus
- Les modules font leur apparition en 2009 avec le projet ServerJS qui changera de nom plus tard pour devenir CommonJS. L’idée était de faire de la programmation javascript sans utiliser des balises scripts. La syntaxe la plus connue de CommonJS est « exports.object = object » pour exporter un « object » et « require(‘module’) » pour importer un module.
- Côté navigateurs est sorti un peu plus tard AMD (Asynchronous Module Definition) qui est un format défini pour charger les modules de manière asynchrone. Elle est implémentée par des librairies comme « require.js ».
- Avec ES6 est arrivée une spécification unifié (que l’on soit côté serveur ou coté client) :
- export, pour exporter des fonctions, des classes ou des variables
- import pour les importer
export class person { … }
import * as people from ‘./person’ ;
var p = new people.person() ;
Si vous souhaitez développer des modules coté client, sans utiliser de frameworks, plusieurs éléments sont à prendre en compte :
Pour les navigateurs qui supportent les modules, ajouter la ligne
<script src='path/to/module.js' type='module'></script>
et pour les autres,
<script src='path/to/nomodule.js' nomodule></script>
La première balise script est asynchrone et charge le fichier module.js après avoir chargé tous les autres scripts (exemples : jquery.js, bootstrap.min.js, etc.) tandis que le second charge directement le fichier ‘nomodule.js’ avant tous les autres.
Cette technique peut engendrer des problèmes de reconnaissance des modules chargés après le rendu des pages. Pour éviter cela, il existe le mot clé « defer »,
<script src='path/to/nomodule.js' nomodule defer></script>
qui rend le chargement asynchrone.
Pour utiliser les modules non supportés par certains navigateurs, il est nécessaire d’utiliser des polyfills ou des bundlers (webpack, rollup ou encore parcel.js).
Ce talk était plutôt intéressant dans la mesure où il permettait de mettre en avant certaines problématiques liées aux chargements de modules javascript.
Fabien Ouedraogo
Tout le monde sait comment utiliser Angular / React / VueJs … mais savez-vous comment utiliser JavaScript ? – Aurélien Loyer & Nathan Damie
Le titre parle de lui même, les développeurs d’aujourd’hui abusent de l’utilisation de frameworks sans forcement maitriser l’utilisation de javascript. Sait-on ce que va retourner le code suivant ?
1+1+(1+true+[]+3+[20]+3)-2
Un boolean ? Une string ? Un nombre ?
A la vue de la réponse, on peut se douter qu’il y a du chemin pour bien comprendre javascript. Et alors qu’est-ce que ça retourne ? Le nombre 223201 à cause d’une série de transtypage à la volée.
Cet exemple est évidemment volontairement complexe mais fait part du constat établi ci-dessus.
Si vous souhaitez revenir aux sources, et que vous n’avez pas forcement besoin d’in framework, vanilla.js est une bonne alternative pour utiliser ce dont vous avez réellement besoin.
Le support de la présentation est disponible ici !
Fabien Ouedraogo
Codelab : Devenez un backend hero avec Kotlin – Grégory Bévan & Thomas Betous
Grégory et Thomas, tous deux formateurs et consultants chez Zenika Nantes, nous ont proposé une session de coding portée sur Kotlin.
Au programme : développement d’un backend (Spring) en Kotlin permettant de tester les capacités des développeurs, type CodinGame. Nous codons donc pour pouvoir apprendre à coder !
Les sources et slides sont disponibles ici.
Arrivés dans la salle, première préoccupation : l’accès à internet. Pas de wifi pour ce Devfest 2018. C’est dans un climat de bonne entente que nous activons et échangeons le partage de connexion de nos portables.
La séance commence par une courte présentation du langage. Orienté objet et fonctionnel, ce langage est releasé dans sa première version par Jetbrains en 2011. Il est propulsé par Google en 2017 durant sa conférence phare : la Google I/O, l’annonçant comme étant le second langage officiellement supporté sur Android.
Nous commençons le codelab, ce dernier se présente sous forme de TPs dont le but est de construire pas à pas notre backend.
Une fois les sources récupérées nous commençons la session. Première surprise : plus besoin de définir une classe pour créer une fonction !
Nous découvrons et codons ensuite avec les notions suivantes :
- val (versus var): de l’immuabilité !
- data class : plus besoin de Lombok ou autre enhancer
- null safety, adieu les NPE ?
- single expression function
- collections
- Et bien d’autres …
Que c’est beau, lisible et moderne !
En conclusion nous repartons avec une bonne base en Kotlin ainsi que des pistes d’apprentissage : coroutines, exceptions, destructuring…
Maxime Delattre
Codelab : Propulsez votre application Angular avec GraphQL et Apollo – Antoine Cellier & Thomas Betous

GraphQL est un langage de requête développé par Facebook, publié en 2015, et constituant une alternative à REST. Il offre la possibilité de formuler la structure de donnée souhaitée en réponse à une requête.
Antoine et Thomas nous proposent de coder avec Apollo, un client permettant d’implémenter nos requêtes GraphQL sur n’importe quel frontend JS.
L’objectif de la session est de réaliser la partie front d’un chatbot.
Les sources et slides sont disponibles à cette adresse
C’est la fin de journée, nous sommes moins nombreux, la fatigue se fait ressentir et le sujet n’en demeure pas moins corsé !
Le codelab commence : nous mettons en place le client Apollo. Ce dernier nous met à disposition une IHM pour nous aider à construire et tester nos requêtes GraphQL.
Nous implémentons ensuite successivement la réception et l’envoi d’un message via des requêtes Apollo. Soit une “query”: getMessages et une “mutation”: saveMessage.
Apollo nous permet simplement d’afficher notre message envoyé grâce à son attribut “refetchQueries” : après un saveMessage, nous refetchons les messages.
Afin d’améliorer les perfs, nous implémentons un cache que nous alimentons avec notre message envoyé : plus besoin de refetch.
Enfin Apollo nous permet de faire de l’optimistic UI avec son attribut “optimisticResponse”. On vient donc simuler une réponse positive du serveur afin d’afficher instantanément notre message envoyé. Remarquons que cette mécanique est utilisée par Facebook et son application Messenger afin d’optimiser son UX.
C’est sur ce dernier point que s’achève ce codelab très fourni techniquement. Les technologies visitées nous permettent de répondre à des problématiques modernes de performances et d’expérience utilisateur.
Maxime Delattre
HTTP/2 – Alexandre Hassler
Slides / Code Source pour les curieux !
La version 2 du protocole http à fait un petit bout de chemin depuis son lancement en 2014. Alexis Hassler, développeur et formateur indépendant se propose de nous présenter les avantages les plus évidents du protocole par rapport à son prédécesseur.
Le multiplexage
Avec http2 on utilise une seule connexion TCP pour faire plusieurs requêtes en parallèle.
http1
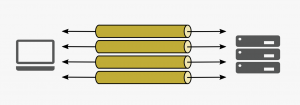
http2
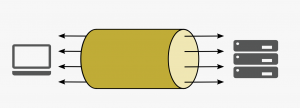
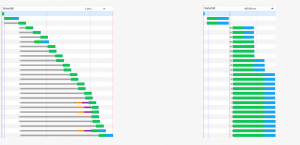
Si on compare le “waterfall” entre une requète http1 et une requête http2, le résultat est sans appel. Cependant on remarquera tout de même que, si l’ensemble des requêtes est traité plus rapidement grâce au multiplexage, le temps de réponse de chaque requête en http2 est plus long :
Les clients http2, h2 ou h2c
Il existe deux versions du protocole : une version avec tls (h2) et la version sans tls dite “clear-text” (h2c). Côté navigateur, h2c n’est pas et ne sera pas supporté; le but affiché étant de forcer l’utilisation de TLS un maximum.
Côté serveur
Il existe une plétaure de solutions pour supporter http2, à commencer par l’implémentation la plus courante : nghttpd. Elle supportera uniquement les requêtes http2. L’implémentation d’apache httpd basée sur nghttpd supporte à la fois h2 et h2c. Attention toutefois, il faudra utiliser openssl pour avoir accès à h2. En effet openssl implémente le protocol ALPN qui permet de négocier une requête entre client et server avant de l’exécuter. Sans ALPN pas de TLS avec http2.
Chez nginx, http2 est supporté par défaut avec le module ngx_http_v2_module.
Côté language et framework, nodeJS est le premier à avoir implémenté le protocole avec le module SPDY, cependant si l’implémentation est disponible depuis la version 8.4 elle est toujours flaggé comme experimental. Chez Java pas d’implémentation d’http2 avant le JDK8 et obligation d’embarquer openssl avant java9. SpringBoot, Vert.X et JEE dans leurs dernières versions implémentent http2.
Push
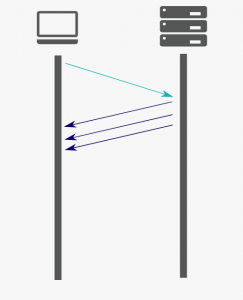
Pour gagner encore plus de ces précieuses millisecondes, http2 permet d’envoyer des ressources statiques au client avant même que ce dernier ne les demande. Le concept paraît alléchant sur le papier mais l’implémentation est fastidieuse ( il faut définir les ressources à pusher pour chaque route, chaque use case…etc) et si notre serveur est derrière un proxy, la gestion du push peut vite devenir un cauchemar.
Http2 derrière un proxy
There is almost no sense to implement it,…
Maxim Dounin (nginx) – déc. 2015
Quand on est à la maison pas de chichi : implémenter http2 pour faire communiquer des serveurs sur un même réseau n’aurait presque aucun intérêt en terme de latence. L’intéret principal serait d’utiliser le push depuis le backend. Malgré les dires de Maxim Dounin, le développement d’un module proxy http2 est en cours chez nginx, et apache met d’ores et déjà le module mod_proxy_http2 à disposition.
Conclusion
Avec http2 le gain de latence client/server est indéniable, en témoigne les nombreuses démos. Cela dit le gain de performance s’accompagne immanquablement d’un coût en ressource et les implémentations d’http2 sont encore, pour la plupart, expérimentales.
Lucas Declercq
Modern API Authentication 101 – Léo Unbekandt
Dans ce talk, Léo Unbekandt (CTO, Scalingo) nous présente une sorte d’état de l’art des méthodes modernes d’authentification d’API.
Chez Scalingo, ils ont d’abord utilisé la méthode du Single API Token : un seul token est utilisé par tous les clients de l’API. Méthode simple et efficace, mais premier problème : lorsqu’il est nécessaire de changer le token, tous les clients sont déconnectés et il faut alors tous les ré-authentifier.

Dans le même ordre d’idée, nous somme aujourd’hui dans un monde multizone (applications réparties sur plusieurs datacenters) et de plus en plus composé de microservices (application constituée de plusieurs composants séparés). Il est alors nécessaire d’avoir un système d’authentification qui permette de s’authentifier une seule fois pour tous ces services et sources de données.
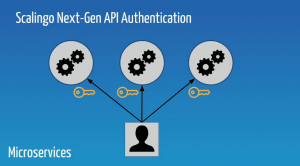
Première solution : les API tokens
On crée un token pour chaque client, ce qui permet de limiter la casse si le token se retrouve dans la nature on ne devra changer le token d’un seul client. Il y a plusieurs façons de communiquer le token à l’API pour s’authentifier :
- Directement dans l’URL (c’est mal ! le token sera alors probablement enregistrés à plusieurs endroits : historique du navigateur, logs d’Apache, etc…)
- Dans le header (c’est mieux !)
Léo nous explique que cette solution est idéale pour les monolithes, ou pour les “intelligent reverse-proxies” (dont voici un exemple) , mais qu’il manque la délégation de l’authentification.
Deuxième solution : OAuth2
L’utilisation d’OAuth permet la délégation de l’authentification (ex: le bouton Se connecter avec Github, Facebook, etc.. présent sur de nombreux sites) pour utilisateur mais aussi et surtout pour un service. On peut ainsi autoriser un service à consommer une API en tant qu’un utilisateur (ex: on autorise Jenkins à utiliser un repository Github) et grâce aux scopes, on peut définir finement quelles permissions sont données à ce service.
Un des avantages d’OAuth est que l’on peut séparer le serveur de ressources et le serveur d’authentification pour gagner en scalabilité et/ou en sécurité.
OAuth2 est une solution très complète (et complexe ?) qui peut s’adapter à de nombreux cas d’utilisations dont Léo nous montre les principaux (cf. le livre OAuth in Action pour aller plus loin)
Troisième solution (la plus optimale) : OAuth2 + JWT
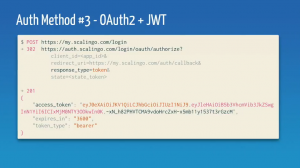
L’utilisation combinée d’OAuth2 et de JWT permet d’ajouter une couche de sécurité complémentaire :
- Le token est signé afin de s’assurer qu’il n’a pas été manipulé par une personne tierce
- On peut plus facilement faire tourner les secrets
Lucas Declercq
Bravo à l’équipe du DevFest 2018 et aux speakers
Nous tenions à féliciter les équipes du DevFest pour le travail qu’ils ont accompli. Nous espérons vous avoir donné envie, à travers la lecture de ce billet, de participer à la prochaine édition de cette conférence avec on l’espère, des goodies aussi funs, des sujets aussi intéressants et une équipe au top !
