J’ai eu la chance d’assister cette année à #DevoxxFR qui s’est déroulé pour la première fois au Palais des congrès, la classe. Le lieu a changé mais l’accueil est toujours chaleureux, café et viennoiseries sont au rendez-vous.
J’avais déjà assisté à Devoxx France il y a 2 ans, et ce que je remarque c’est qu’il y a bien plus de sessions web que les années précédentes et pour ma part je trouve que c’est une très bonne chose car ça reflète bien les tendances actuelles.
Pour ma part, Devoxx a été synonyme d’asynchronisme (autant côté client que server), de performance, d’architecture mais aussi de sécurité.
L’asynchronisme…
…dans notre bon vieux navigateur
BlueBird
Si vous n’êtes pas encore familier avec les promesses/promises, je vous conseille de vous y mettre car demain elles seront nativement gérés par tous nos navigateurs comme prévus par la nouvelle spécification ECMASCRIPT 6/2015.
Support des promises par les navigateurs
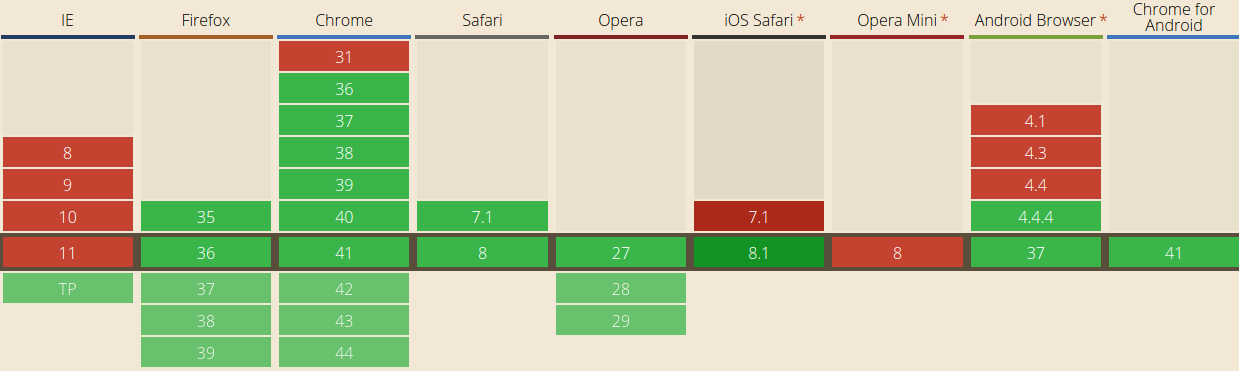
En attendant, plusieurs librairies proposent leur propre implémentation des promesses et ce depuis plusieurs années. La plus connue et répandu d’entre elles est Q (prononcé en anglais pour queue), que je connaissais pour ma part au travers du module AngularJS $q. Celle-ci est relativement complète et simple d’utilisation, par contre dès lors que l’on souhaite faire des choses un peu moins basiques, on se trouve assez limité.
Et c’est là que BlueBird intervient !
Il est possible de spécifier une limite d’appels concurrents lorsque plusieurs promesses doivent être exécutées.
Par exemple : je souhaite exécuter N promesses mais je veux qu’elle s’exécute par paquet de 3 pour accélérer l’affichage et procurer un confort à l’utilisateur.
La fonction .join permet de coordonner plusieurs promesses. Vous allez dire, “Mais il y a le .all pour ça !?”. Le .all est bien pour la manipulation d’une liste de taille dynamique de promesses uniformes. Par contre le .join est beaucoup plus simple à utiliser et plus performant lorsque vous connaissez le nombre de promesses à exécuter.
A noter que la librairie s’utilise via la variable globale Promise (ou P) et qu’un certain nombre de méthodes non autorisées par des navigateurs sous ECMASCRIPT 3 (comme IE8 par exemple) sont remplacées. Par exemple .catch est remplacé par .caught et .finally par .lastly. La documentation de l’API référence les alternatives à ces mots clés.
…dans notre chère JVM
RxJava
Il s’agissait d’un hands on lab, on a donc mis les mains dans ReactiveX et personnellement je connaissais vaguement au travers de Hystrix mais le contenu de la présentation était très intéressant.
Le framework est basé sur le pattern Observable afin de permettre de faire de l’asynchronisme et de développer des applications dites réactives.
Durant ce lab, nous avons développé une application cliente qui appelait des services non fiables. Le but était donc de démontrer l’intérêt de RxJava dans ce contexte qui offre beaucoup de fonctionnalité, entre autre de rééxécuter un appel ayant échoué (Retry), d’éviter les points de contentions ou encore de définir un timeout sur un observable.
La performance
Hashons peu mais hashons bien
Durant cette présentation, nous avons pu voir l’importance que l’on doit porter aux tables de hachage, notamment lorsque l’on manipule de très gros volume de données.
En effet, l’allocation de la mémoire joue un rôle essentiel dans les performances. Sa capacité initiale a donc son importance, par défaut celle d’une HashMap est de 16, mais elle peut être redéfinit. Attention à ne pas mettre trop ou pas assez car cela peut avoir une incidence certaine sur la ré-allocation de la mémoire. Lorsque la map atteint sa taille limite la nouvelle capacité est la capacité initiale définit multiplié par 2. Donc si la capacité initiale est de 1, et que la taille de la map atteint 1000, nous allons effectuer 10 (1*2*2*2*2*2*2*2*2*2*2 = 1024) calculs de trop. A l’inverse, si on réserve un espace trop important, on risque de polluer inutilement la mémoire.
Aussi, il est important, non pas primordial, de redéfinir les méthodes hashCode() et equals(), et ce pour des raisons de performance et de cohérence des données car les opérations de recherches se basent sur ces méthodes, et cela peut avoir une influence sur la rapidité d’exécution de ces opérations. Sans entrer dans le détail, le hash va permettre de constituer des sous-ensembles afin d’accélérer la recherche. Au lieu de tester toutes le voitures d’un parking avant de trouver la nôtre, on se repère à une rangée, ce qui accélère grandement notre recherche.
Cachons peu mais cachons bien
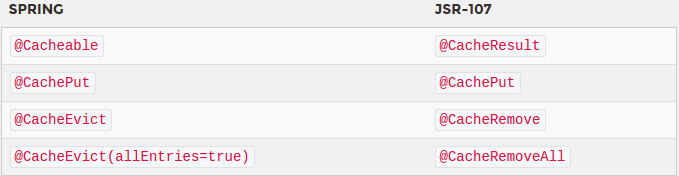
Nous avons tous déjà mis ou voulu mettre du cache dans notre application. Nous avons tous notre petit framework ou encore nos classes utilitaires pour le faire. Malgré qu’il y ait énormément de manière de faire du cache, il existe bien une spécification, la jsr-107 ou JCache. A la base un peu poussiéreuse car datant de 2001 mais mise à jour en Mars 2014, celle-ci a été implémenté par les frameworks les plus connus : Spring, EhCache, Guava…
Personnellement, j’ai déjà utilisé ces 3 frameworks de cache, soit avec leurs propres annotations, soit via leurs propres méthodes. Chacun d’entres eux s’utilisent donc différemment mais fait globalement la même chose, du cache. L’intérêt de la spécification vous l’aurez compris, est de pouvoir changer d’implémentation assez facilement, sans modifier le code.
Support des annotations de la jsr-107 par Spring
Architecture
J’ai assisté aussi à la présentation de Hadi Hariri, qui travaille chez Jetbrains, sur le refactoring fonctionnel.
“La programmation fonctionnelle est un paradigme de programmation qui considère le calcul en tant qu’évaluation de fonctions mathématiques et rejette le changement d’état et la mutation des données. Elle souligne l’application des fonctions, contrairement au modèle de programmation impérative qui met en avant les changements d’état.” Wikipédia.
L’idée principale de cette approche, est que tout est fonction qui prend N arguments en entrée et ne retourne qu’une seule et unique valeur en sortie, et ce sans conserver le moindre état. Ces fonctions sont dites “pures”. C’est à dire qu’elles retournent toujours le même résultat pour les mêmes paramètres en entrées et ne doit en aucun cas dépendre de quelque chose qui n’est pas directement en entrée. De cette manière, la succession d’appels de fonctions simples, répond à des problématiques complexes sans maintenir le moindre état.
Les avantages sont nombreux dans cette approche. Le code que nous écrivons est plus concis, plus lisible et “human readable”. N’importe qui peut lire et comprendre votre code, non seulement un autre développeur peut plus facilement maintenir votre code mais en plus votre chef de projet fonctionnel peut avoir un accès sur votre repository de sources. Un autre avantage est la testabilité du code que l’on produit étant donnée que les méthodes sont plus simples, les tests unitaires le deviennent naturellement.
Hadi Hariri a choisi Kotlin, le langage fonctionnel développé par Jetbrains, pour illustrer ses exemples mais ça n’a pas trop d’importance. On peut très bien faire de la programmation fonctionnelle avec d’autres langages tels que Scala, Haskell, Groovy ou encore Java 8 et ses fameuses Lambas expressions. Il existe certains frameworks tels que Guava qui contiennent des fonctions dîtes supérieur, c’est à dire des fonctions qui prennent en paramètre d’autres fonctions, afin de permettre un développement fonctionnel en Java 1.6+.
Nous avons pu voir durant cette conférence que le refactoring fonctionnel n’est pas si compliqué, et même en Java, qui n’est pas à la base un langage fonctionnel. Il peut s’avérer légèrement moins performant à l’exécution que la programmation événementielle (car on répète potentiellement les opérations de parcours de collections…), en revanche le code produit est plus concis et lisible.
La sécurité
J’ai été assez interpellé par la keynote d’Eric Filiol, “La problématique du contrôle des technologies de l’information”.
“Qu’on me donne six lignes écrites de la main du plus honnête homme, j’y trouverai de quoi le faire pendre.” Cardinal Richelieu
Keynote qui fait réfléchir sur notre responsabilité, à nous développeur #DevoxxFR pic.twitter.com/JO75f0EEr5
— Azize Elamrani (@azize_elamrani) 9 Avril 2015
Son intervention m’a personnellement fait réfléchir sur le code que j’ai pu écrire précédemment et qui pourrait porter atteinte à la vie privée ou à la sécurité d’autrui. C’est une réflexion que je n’avais jamais eu et certainement à tord car nos données personnelles sont de plus en plus exposées, transitent parfois par des canaux non sécurisés, et peuvent être utilisés à mauvais escient.
“va-t-on rester des veaux connectés”
Ok. Nous sommes tous d’accord qu’il faut de la sécurité, et que nous disposons de moyens technologiques qui nous permettraient assez facilement de surveiller les communications. Mais cette surveillance ne risque-t-elle pas d’avoir l’effet inverse (en créant des failles) et de porter atteinte à la vie privée ? C’est un sujet d’actualité qui ne laisse personne indifférent et même le gouvernement s’en empare pour justifier le contrôle qu’il souhaite imposer aux citoyens avec le fameux projet de loi renseignement.
