L’édition de Devoxx France 2015 est terminée, place au bilan. Nous étions 4 à y assister cette année avec tout particulièrement la sélection d’Hubert Sablonnière pour 2 talks de grande qualité.
Voici ce que j’ai retenu en particulier.
Application Réactive
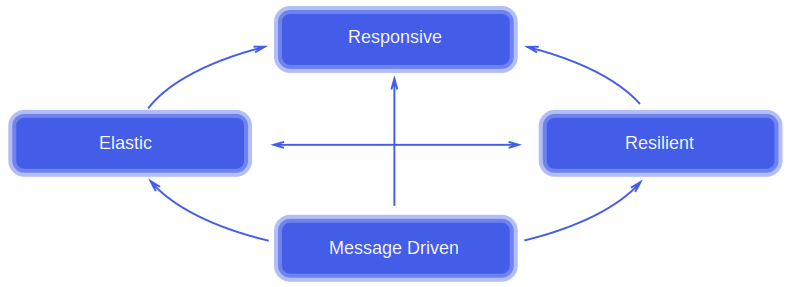
L’application cible souvent présentée durant les conférences se devait d’être réactive au sens du Reactive Manifesto. Elle se doit d’être :
- Responsive: consistence des temps de réponse et traitement des erreurs
- Resilient: isolation des composants et découplage fort
- Elastic: scalabilité du système et donc design qui évite les points de contention. Egalement un monitoring performant pour gérer la scalabilité et les coûts
- Message Driven: Les composants du systèmes doivent communiquer par messages asynchrones, rien ne doit être bloquant

Message Driven
Plusieurs sessions ont présentés des outils/frameworks permettant de mettre en œuvre un système orienté message. Évoquons tout d’abord kafka.
Initialement développé par LinkedIn, open-sourcé en 2011 puis hébergé par la fondation Apache en 2012, Kafka est un broker de message qui a pour objectif de fournir une plateforme distribuée haut débit pour la distribution de message.
En résumé, le producer envoi un message à un topic, kafka log le message dans un fichier plat et le distribue. Les consumer vont interroger le topic pour récupérer les messages. Ce n’est pas le broker qui pousse l’information aux consumer, mais bien les consumer qui vont tirer l’information. Ce midlleware est parmi les plus performants dans les benchs évaluant la consommation de message.
Un autre framework pour développer des applications orientées message est Vert.x. Vert.x est une plateforme tournant sur la JVM offrant un bus d’évènements permettant de faire communiquer des “Verticle” entre eux de façon asynchrone. Votre application peut être écrite dans de nombreux langages (java, javascript, ruby, python, groovy, clojure, scala, ceylon) et votre code existant peut être embarqué dans un Verticle pour pouvoir ainsi profiter du bus d’événement.
Elastic
La scalabilité du système tient en grande partie à la scalabilité de l’infrastructure. Il a beaucoup été question de Mesos dans les talks.
Mesos permet d’abstraire l’infrastructure sous forme de ressources (une ressource déclare par exemple ses cpu, sa ram et son disque) et d’exécuter des tâches sur ces dernières.
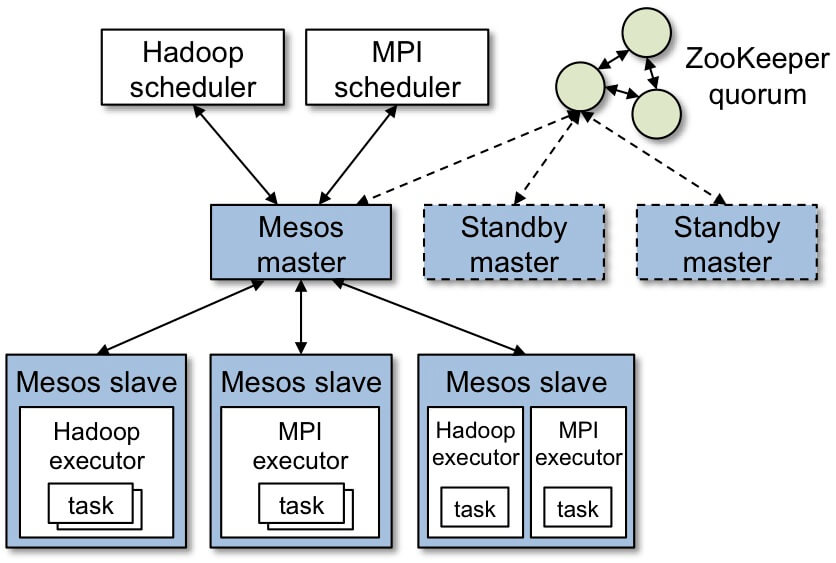
Le Mesos Master (en mode actif/passif pour assurer sa disponibilité) échange avec les Mesos Slave pour maintenir l’état des ressources disponibles.
Un framework (composé d’un scheduler et d’un executor) va permettre d’effectuer des tâches sur les ressources: un traitement de type batch, qui aura une durée de vie courte ou bien un déploiement de webapp qui aura une durée de vie longue.
Voici la cinématique pour effectuer une tâche :
- Le scheduler s’enregistre auprés du Mesos Master
- Le scheduler reçoit du Mesos Master les ressources disponibles
- Le scheduler choisit une ressource et indique au Mesos Master qu’il souhaite lancer une tâche dessus
- Le Mesos Master transmet au slave la/les tâches à effectuer
- L’executor du Slave traite la tache
Mesos permet donc d’avoir une abstraction de son infrastructure et une réelle optimisation des ressources. Son implémentation ne se fait par contre pas dans la simplicité. En effet le provisionning des machines n’est pas du domaine de Mesos, il faudra donc mettre en place des outils comme Chef, Puppet ou Ansible pour cela. De même, pour assurer la haute disponibilité, la mise en place de Zookeeper afin d’assurer la synchronisation des Mesos Master est indispensable.
Les scheduler pourront également être tolérant à la panne et un cache distribué permettant de conserver leur contexte lors d’un crash peut également être nécessaire.
Enfin, comme on ne sait pas où s’éxécute la tâche, le monitoring et la gestion des logs sont un vrai chantier dans ce type de projet afin de conserver une maîtrise de l’environnement.
Bref comme l’a indiqué le speaker, la mise en place se fait dans la douleur, le sang et les larmes, mais une fois en place, c’est un bonheur. La démonstration d’un arrêt de conteneur web et même de la destruction totale d’une instance Amazon donne envie d’essayer. De plus, les problématiques évoquées ci dessus (provisionning, monitoring, …) sont en général déjà adressées dans les datacenter de plusieurs centaines de machines.
Resilient
La résilience est la capacité du système à faire face à la défaillance d’un élément. Si un web service met du temps à répondre et que rien n’est mis en place, les appels à se dernier vont s’empiler et les threads de la jvm étant limités, c’est tout le système qui risque d’en pâtir. Et si en plus ce web service n’est pas vital pour votre application, il y a forcément quelque chose à faire.
Un pattern a été présenté, le circuit breaker. C’est le principe du fusible en électricité. Quand un problème est détecté, le fusible saute et le reste de l’installation continue de fonctionner. Le problème est isolé derrière le fusible.
Le principe peut donc être mis en œuvre dans une application : détecter un problème (la base de données ne répond pas ou bien un web service est trop lent), stocker cette information et la tester avant chaque appel au sous système.
L’implémentation peut être faite à l’aide du framework Hystrix (développé par Netflix).
Hystrix est une librairie qui encapsule vos appels et permet entre autre de rendre leur exécution asynchrone, de placer des timeout sur les appels et de gérer les fallback en cas d’erreur.
Un système résilient est en général un sytème à base de micro service.
Continuous Delivery
Le jeudi soir avait lieu un BoF sur le nouveau plugin de création de workflow qui fait rentrer Jenkins dans la compétition des outils de delivery. Ce plugin amène un DSL groovy permettant de coder le workflow, l’exécution de tâche en parallèle sur différents nœuds et voir l’état d’avancement.
C’est une réelle avancée par rapport aux nombreux plugins permettant de modéliser un workflow à l’aide de jobs. Un plugin à suivre et à déployer !
A noter que les 2 principaux ingénieur de Cloudbees (Kohsuke Kawaguchi et Jesse Glick) sont également les 2 principaux committer du projet.
Pour terminer sur le Continuous Delivery, l’équipe des Furêts a présenté leur façon de merger en continue grâce à leur script git octopus. Ils livrent en production tous les jours et leur workflow de branche et de merge est le suivant :
Features branching chez http://t.co/mvlhbeQUzk #DevoxxFR cc @BrunoLavit pic.twitter.com/jNX4EpepJk
— Laurent Bristiel (@LaurentBristiel) 10 Avril 2015
Toute demande est trackée dans leur jira et une branche est crée pour chaque ticket. Une branche par développeur.
Toutes les branches en cours sont mergées en continue grâce à octopus et le merge est “force pushé” sur une branche octopus-features du repo features, qui sera ensuite déployée et testée sur un environnement de QA.
Ensuite, lorsqu’un ticket est éligible à la mise en production, la branche est poussée sur le repo releases et git octopus entre à nouveau en action. Le résultat est poussé sur master pour boucler le workflow et entamer un nouveau cycle de release.
Ce workflow est très intéressant mais nécessite quelques prérequis :
- Une seule codebase pour le site, donc un ticket métier ne concerne qu’une seule branche d’un seul repo git
- Utilisateur de maven comme outil de build, ils sont toujours en version snapshot, évitant ainsi d’avoir les éternels conflits de merge sur version des pom.xml
- un postulat de base : un ticket ne corrige pas le bug introduit par un autre. Les tickets sont tous recettés ensemble mais seuls quelques uns partiront en production. La probabilité qu’un bug apparaissent parce qu’un autre ticket n’a pas été livré est nulle.
Références
Trois heures à l’assaut d’une application réactive
Applications Concurrentes Polyglottes avec Vert.x
Jenkins workflow – a first class DSL for programming your pipelines
